이미지 압축은 이미지 데이터를 더 작은 크기로 줄이는 기술입니다. 이미지는 픽셀로 구성된 2차원 행렬로 표현됩니다. RGB 이미지의 경우 한 픽셀은 세 개의 채널 \( (R, G, B) \)로 구성된 행렬입니다. 만약 압축을 하지 않는다면 한 픽셀당 3 byte의 데이터가 필요합니다. 예를 들어, 1920x1080 해상도의 이미지는 대략 6.2MB의 크기를 가집니다. 압축 기술이 없다면, 이러한 이미지는 굉장히 많은 용량을 차지합니다. 24프레임 영상의 경우 1초당 148.8MB, 1분당 8.7GB의 용량이 필요합니다.
Singular Value Decomposition
SVD(특이값 분해)는 행렬을 세 개의 행렬로 분해하는 방법입니다. 임의의 \( m \times n \) 행렬 \( A \)를 특이값 분해하면 다음과 같이 표현할 수 있습니다:
\( U \)는 \( m \times m \) orthogonal(직교) 행렬, \( \Sigma \)는 \( m \times n \) 대각 행렬, \( V^T \)는 \( n \times n \) orthogonal 행렬입니다. 여기서, \( \Sigma \)의 대각 원소들은 \( A \)의 특이값(singular value)라고 부릅니다.
SVD를 수행하는 과정은 먼저 \( A^T A \)와 \( A A^T \)의 eigenvalue(고유값)와 eigenvector(고유벡터)를 계산하는 것입니다. \( A^T A \)의 고유벡터는 \( V \)의 열이 되고, \( A A^T \)의 고유벡터는 \( U \)의 열이 됩니다. 특이값 \( \sigma_i \)는 \( A^T A \)의 고유값의 제곱근입니다. 편의를 위해 내림차순으로 정렬합니다.
예를 들어, 다음과 같은 \( 4 \times 4 \) 행렬이 있다고 가정해봅시다:
\( A^T A \)의 eigenvalue는 \( [1, 4, 0, 0] \)이므로 singular value는 \( [2, 1, 0, 0] \)입니다. 따라서, 다음과 같이 표현됩니다.
SVD는 행렬 \( A \)를 \( \mathbb{R}^n \)에서 \( \mathbb{R}^m \)로 매핑하는 선형 변환으로 해석할 수도 있습니다. 먼저 \( V^T \)가 입력 벡터를 회전시키고, \( \Sigma \)가 각 축을 따라 스케일링을 수행하며, 마지막으로 \( U \)가 \( m \)차원 공간에서 회전시키는 과정입니다.
SVD Compression
SVD 수식을 다시 살펴보면, 다음과 같이 표현할 수 있습니다
이때, 앞서 singular value \( \sigma_i \)는 내림차순으로 정렬되어 있습니다. 즉, \( u_1 \)이 가장 중요한 방향입니다. 여기까지의 내용을 파이썬으로 구현해보겠습니다. 먼저 임의의 데이터를 준비합니다.
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
N = 50
x = np.random.normal(0, 5, N)
y = 2 * x + np.random.normal(0, 4, N)
# 중심을 0으로
x -= np.mean(x)
y -= np.mean(y)
plt.scatter(x, y)
plt.show()
이 데이터에 대해서 SVD를 수행합니다.
a = np.array([x, y])
u, s, vt = np.linalg.svd(a)
print(u.shape, s.shape, vt.shape)
print(s)(2, 2) (2,) (50, 50)
[78.66883877 10.10746124]\( \Sigma \)는 원래 대각 행렬이었지만, linalg에서는 대각 원소만 반환합니다. \( 2 \times 50 \) 크기의 행렬이었으니 2개의 singular value가 존재합니다. 첫 번째 singular value가 두 번째보다 훨씬 크다는 것을 알 수 있습니다.
SVD 압축은 singular value가 점점 작아지는 점을 이용해서 작은 singular value를 제거하는 방식으로 압축을 진행합니다. 예를 들어, \( k=1 \)로 압축을 한다면, 다음과 같이 표현할 수 있습니다.
2차원이어서 데이터가 많이 없으니 실제 이미에 적용을 해보겠습니다.
import cv2
img = cv2.imread("lenna.png", cv2.IMREAD_GRAYSCALE)
print(img.shape)
plt.imshow(img, cmap='gray')
plt.show()
이 이미지는 \( (500, 500) \) 크기의 그레이스케일 이미지입니다. 마찬가지로 SVD를 수행합니다.
u, s, vt = np.linalg.svd(img)
print(u.shape, s.shape, vt.shape)
# (500, 500) (500,) (500, 500)여기서 500개의 singular value를 사용하지 않고 단 1개만 사용하면 어떤 이미지가 나올까요?
recon_img = np.matrix(u[:, :1]) * np.diag(s[:1]) * np.matrix(vt[:1, :])
plt.imshow(recon_img, cmap='gray')
plt.show()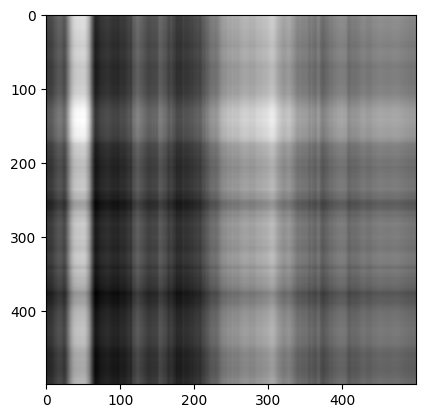
직교 형태의 이미지가 나왔습니다. 대충 원본 이미지의 밝기가 표현된 것 같습니다. 여기서 singular value를 담고 있는 s를 한번 살펴보도록 하죠.
plt.figure(figsize=(8, 4))
plt.subplot(1, 2, 1)
plt.plot(range(1, len(s) + 1), s)
plt.title("Singular Values")
plt.subplot(1, 2, 2)
plt.plot(range(1, len(s) + 1), s)
plt.yscale('log')
plt.title('Singular Values (log scale)')
plt.tight_layout()
plt.show()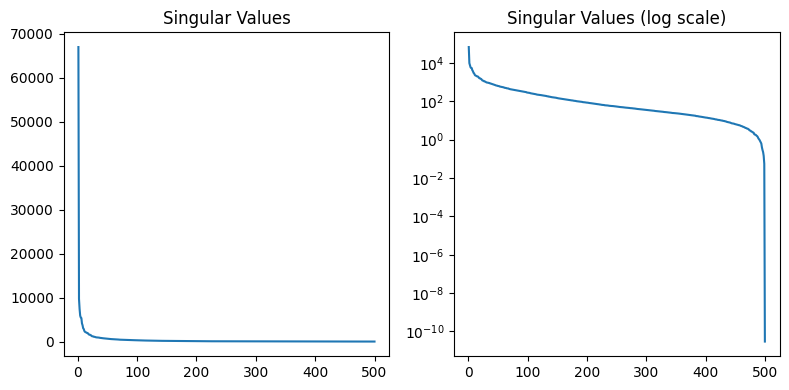
초반엔 큰 값을 보이고 있지만, 이후로는 급격히 작아지는 것을 볼 수 있습니다. 즉, 작은 singular value를 제거해도 손실되는 정보가 많지 않다는 뜻입니다. \( k \)를 늘려가며 복원된 이미지를 살펴보겠습니다.
m, n = img.shape
total_energy = np.sum(s**2)
plt.figure(figsize=(16,4))
start, end, step = 10, 110, 25
for idx, i in enumerate(range(start, end, step)):
plt.subplot(1, (end - start) // step + 1, idx + 1)
recon = u[:, :i] @ np.diag(s[:i]) @ vt[:i, :]
plt.imshow(recon, cmap='gray')
# 압축률
compressed_size = i * (m + n + 1)
original_size = m * n
compression_ratio = compressed_size / original_size
# 정보 보존율 / 손실률
retained_energy = np.sum(s[:i]**2) / total_energy
loss = 1 - retained_energy
plt.title(
f'k={i}\n'
f'comp={compression_ratio*100:.1f}%\n'
f'loss={loss*100:.2f}%'
)
plt.tight_layout()
plt.show()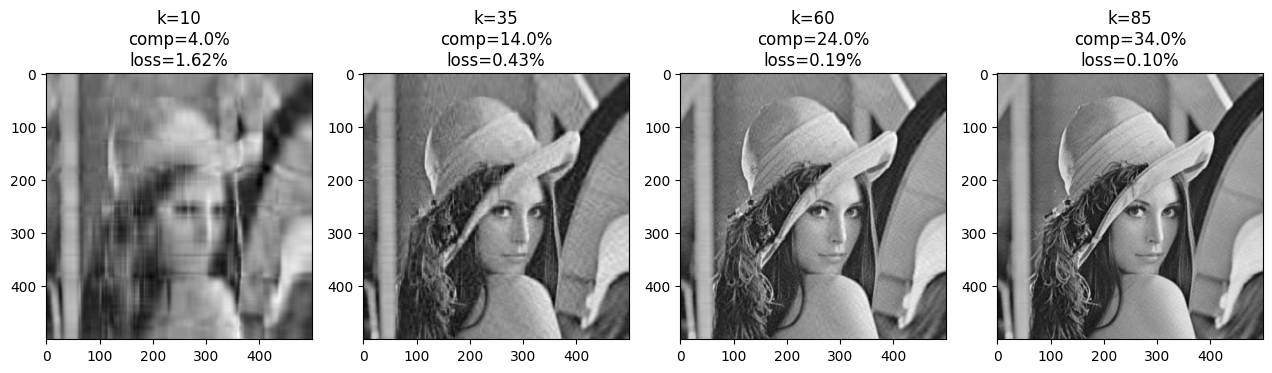
점점 많은 singular value를 사용하면서 원본 이미지에 가까워지는 것을 볼 수 있습니다. \( k = 85 \) 에서는 원본과 차이를 느끼기 힘듭니다. 이때의 용량은 원본의 34%고, 손실률은 0.1%입니다. 용량은 1/3으로 줄였지만 데이터는 거의 보존할 수 있었네요.